아래 포스트에서 이어지는 글입니다.
To-do 리스트 프로젝트 회고 - (1) 시작
4월 셋째주의 금요일인 오늘, 코드스쿼드에서 진행하는 프로젝트 과정의 첫번째 To-do 리스트 프로젝트가 끝났다. 이번 프로젝트에는 백엔드 2명, 프론트엔드 2명이 함께 참여했고, 웹 애플리케이
rxdcxdrnine.tistory.com
이번 포스트에서는 코드스쿼드의 첫 프로젝트로 진행한 To-do 리스트 프로젝트에서 기능을 구현하기 위한 여러가지 방법을 놓고 고민한 부분과, 기술적으로 다루거나 알게된 점들을 위주로 회고를 작성해보고자 한다.
칸반 보드 이동 구현하기
To-do 리스트 애플리케이션을 만들면서 구현하기 어려웠던 기능은 역시 '카드의 이동' 이었다. 프로젝트의 기획서를 처음 받았을 땐, 단순히 카드 (Card) 테이블 내에 칸반 보드의 컬럼 (Column) 내에서 순서를 나타내는 애트리뷰트를 만들고, 숫자로 순서를 관리하면서 조회 시에는 순서에 따라 정렬하면 될 것같다고 막연하게 생각했다. 하지만 실제로 기능을 구현하기 위해 특정 카드를 다른 컬럼으로 이동하거나 같은 컬럼 내에서 순서를 변경할 때, 각 케이스마다 다른 SQL 문을 실행해야한다는 것을 알게 되었다.
그림으로 나타내면 다음과 같다.

같은 색의 SQL 문은 동일한 SQL 문인데, 카드를 다른 컬럼으로 이동할 때와 같은 컬럼 내에서 순서만 바꿀 때에 카드의 이동에 영향을 받는 카드의 데이터를 업데이트하기 위해 각 케이스마다 다른 SQL 문을 실행해야 한다. 비록 생각하기 쉬운 방법일 수는 있어도, 데이터베이스에서 실행할 쿼리를 관리하는 애플리케이션 서버 내의 데이터 계층에서 각 케이스를 위해 여러 오퍼레이션을 만들어야 한다. 그리고 카드를 이동할 때 이동하는 컬럼이 동일한지, 다른지 구분하기 위해 분기문을 작성해 절차지향적인 코드가 작성된다는 단점이 있다.
이에 대한 대안으로 아래의 2가지 방법을 생각해 볼 수 있다.
1. 순서를 큰 수의 인덱스로 관리하기
이 방법은 순서 애트리뷰트를 1, 2, 3, 4, ... 와 같이 연속된 정수가 아닌 10000, 20000, ... 과 같이 큰 수의 인덱스로 간주한다. 초기에 정렬된 카드 순서를 10000, 20000, ... 의 인덱스로 부여하고, 만약 첫번째 카드와 두번째 카드 사이에 새로운 카드가 이동해 추가되면 해당 카드의 순서를 15000 으로 부여하는 방식이다. 매번 카드 사이에 절반에 해당하는 인덱스를 부여하면서, 모든 카드가 이동한 후에 사용자가 서비스를 종료할 때 최종적으로 순서를 업데이트한다. 카드의 순서 값이 10000, 15000, 20000, ... 인 상태에서 10000, 20000, 30000, ... 으로 새롭게 순서 인덱스가 부여된다.

해당 방식으로 순서를 부여할 경우, 기본적으로 배치 작업으로 처리해야한다. 사용자가 카드를 이동시킬 때마다 이동하는 카드의 순서 애트리뷰트만 업데이트하고 주변의 다른 카드는 업데이트하지 않는데, 어떤 두 카드 사이에 다른 카드를 넣게 되면 이동한 카드의 순서값을 (양 옆의 두 카드의 순서 값의 합/2) 로 업데이트한다. 그리고 사용자가 카드를 여러번 이동시키고난 후 사용을 종료하면, 배치 작업으로 컬럼 내 모든 카드의 순서를 조사해 새로운 순서에 따라 1000, 20000, 30000, ... 의 값으로 카드의 순서 애트리뷰트를 업데이트한다.
대신에 위의 그림과 같이 어떤 카드 사이에 13개의 카드가 추가된다면, 이후에 추가되는 카드의 경우에는 컬럼 내의 다른 카드와 순서가 일치하게 된다. 따라서 카드와 카드 사이에 추가될 수 있는 카드의 개수를 제한하거나, 순서 인덱스의 단위를 10000 이상으로 늘려야하는 단점이 있다. 그리고 배치 작업을 하더라도 각 컬럼 별로 카드를 정렬한 뒤에 카드의 순서에 따라 각 카드마다 UPDATE 문을 실행해야 한다. 따라서 배치작업이더라도 O(column X card) 만큼의 SQL 문 실행이 일어나야하므로 비용이 꽤 발생하는 편이다.
2. 카드를 연결 리스트 방식으로 관리하기
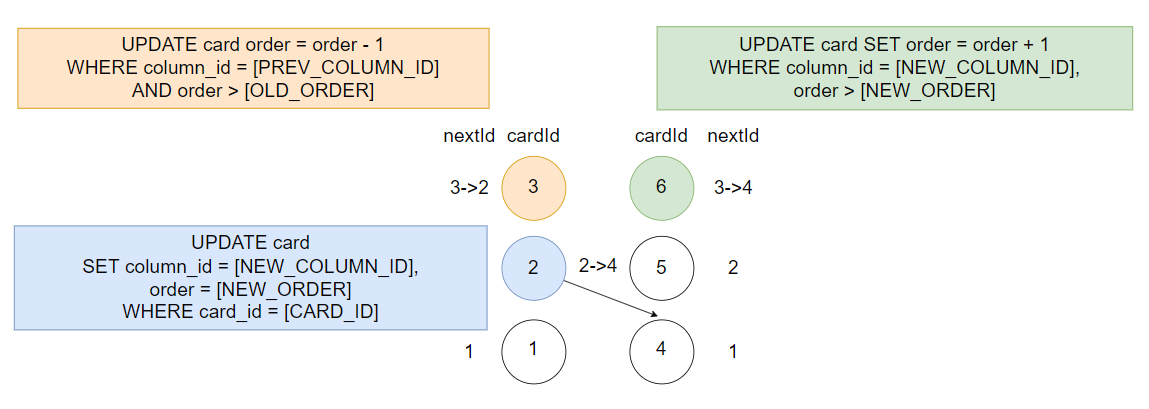
컬럼 내 카드를 연결 리스트로 방식으로 관리하면, 순서 애트리뷰트 대신 다음 카드의 Id (nextId) 를 카드 테이블의 애트리뷰트로 추가한다. 즉, 컬럼 내에서 어떤 카드의 아래에 있는 카드의 Id 값을 nextId 의 값으로 가진다. 자연스럽게 맨 아래에 있는 카드의 경우, 더 아래에 있는 카드가 존재하지 않으므로 nextId 의 값이 null 이다. 해당 방식으로 카드의 순서를 관리할 떄 카드를 이동시키면 아래와 같이 SQL 문을 실행하게 된다.


처음의 방식과 다르게 모든 케이스에 대해 항상 같은 SQL 문을 실행할 수 있다. 그리고 SQL 문이 실행되는 순서를 고려하지 않아도 된다. 단, 카드를 컬럼의 맨 위에 추가하거나, 컬럼 중간의 카드를 삭제할 때 주변의 다른 카드를 조회해야하거나 링크를 새로 업데이트해야하는 등 연산이 더 추가되는 단점이 존재한다.
하지만 연결 리스트 방식을 사용하면 카드의 이동 시에 비즈니스 로직을 더 단순하게 생각할 수 있고, 모든 케이스에 대해 분기처리 없이 일관된 코드를 작성할 수 있으므로 우리 팀은 연결 리스트 방식으로 카드의 순서를 관리하기로 결정했다.
페이징 구현하기
To-do 리스트 애플리케이션에서는 사용자가 카드를 추가하거나, 이동하거나, 삭제하는 등의 액션이 일어날 때마다 히스토리 (History) 가 오른쪽 탭에 추가되는 기능이 요구되었다. 그리고 사용자가 최초로 애플리케이션을 실행했을 때 (웹 브라우저로 접속했을 때), 저장되어 있던 히스토리 내역을 모두 불러와야 했다. 하지만 유저별로 데이터베이스에 저장된 히스토리 내역을 모두 불러오게 되면 한꺼번에 너무 많은 데이터가 클라이언트에 전송되어야하므로 데이터베이스-서버, 서버-클라이언트 사이에 많은 통신 비용이 발생한다. 이를 해결하기 위해 페이징의 개념을 도입해 클라이언트가 다음 페이지를 요청하면 해당 페이지의 히스토리 내역을 보여주는 방식으로 구현을 변경했다.
그런데 히스토리 정보는 사용자가 액션을 취할 때마다 기능에 해당하는 API 로 클라이언트의 요청에 대한 응답으로 주어지며, 히스토리 내역에서 위쪽으로 계속 추가되고 데이터베이스에도 저장된다. 하지만 페이징을 구현하기 위해서는 아래로 데이터가 추가되어야 하므로, 클라이언트에서 기존의 페이지 번호를 기준으로 다음 페이지를 요청하게 되면 기존의 히스토리 내역과 다음 페이지의 히스토리 목록은 일부가 겹치게 되는 문제가 발생한다.

이를 해결하기 위해 기존의 페이징 개념을 그대로 도입하기보다, 살짝 변형해서 클라이언트에서 현재까지 저장된 히스토리 내역의 개수를 히스토리 목록을 불러오는 API 의 요청에 포함하도록 구현했다. 이렇게 하면 클라이언트에 저장된 히스토리 내역에 최신 액션에 대한 히스토리가 추가되더라도, 추가된 만큼 늘어난 히스토리 내역의 개수를 요청하므로 다음 히스토리 목록을 페이지 단위를 불러올 때 겹치지 않는다. 예를 들면 페이지 내 데이터 개수가 10개이고 유저의 액션에 따라 그림처럼 4개의 데이터가 추가되었다면, 다음번에 5~14번째 히스토리 내역 목록을 읽어오는 방식이다.
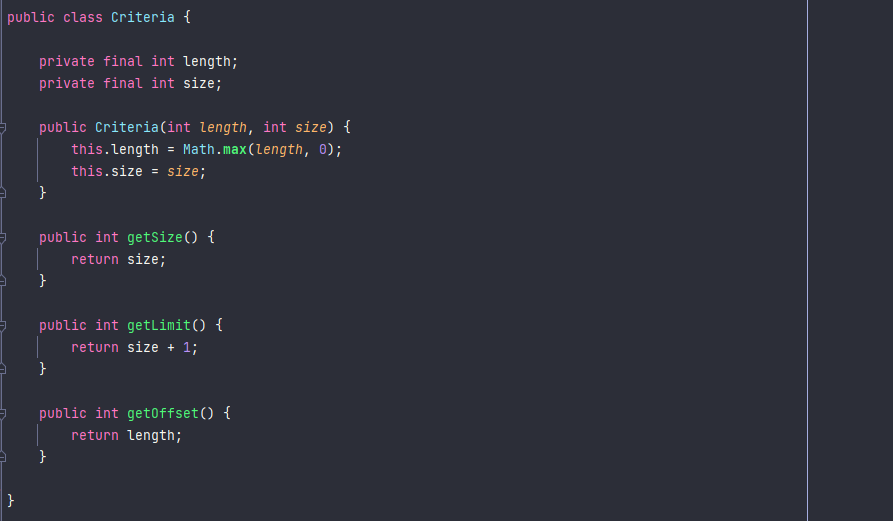
그리고 페이징 구현 시에 먼저 유저에 대한 전체 히스토리 테이블 내 레코드의 개수를 읽어온 뒤에 현재 페이지 정보를 계산하지 않고, 페이지 내 데이터 개수가 10개라면 11개의 히스토리 테이블 내 레코드를 데이터베이스에 요청한 후에 실제로 데이터가 11개로 오는지를 검사하도록 구현했다. 만약 11개를 읽어온다면 현재 페이지 이후에 데이터가 더 있다는 의미이고, 11개보다 적게 읽어온다면 현재 페이지가 마지막 페이지라는 의미가 된다. 이를 코드로 구현하면 다음과 같다.

N+1 문제 해결하기
위의 히스토리 내역은 한가지 문제를 더 안고 있다. 서버 애플리케이션 코드에서 데이터베이스에 SQL 쿼리문을 반복적으로 호출할 때 일어날 수 있는 N+1 문제가 그것이다. 히스토리 내역에 해당하는 History 테이블은 Card 테이블 내 특정 필드의 변경 내역을 저장하는 ModifiedField 테이블과 1:N 의 관계를 가지며, 데이터베이스 스키마 구조로 표현하면 아래와 같다.

만약 History 테이블을 페이징을 이용해 조회할 때, History 테이블의 PK (Primary Key) 마다 ModifiedField 테이블의 history_id 필드에서 FK (Foreign Key) 로 가지는 레코드가 있는지 조회한다고 가정한다. 먼저 History 테이블에서 조회할 때 1번, 그리고 조회된 History 레코드 N개에 각각에 대해 다시 ModifiedField 테이블을 매번 조회한다면 총 쿼리문 실행횟수는 N+1번으로 데이터베이스 연결이 불필요하게 자주 일어나게 된다. 따라서 이를 해결하기 위해, 다음과 같이 조회 로직을 구성했다.

먼저 History 테이블을 조회한 후에 반환된 History 레코드 목록에서 Id 애트리뷰트만 리스트로 추출한다. 그리고 Id 리스트 내의 History Id 를 ModifiedField 테이블에서 FK 로 가지는 ModifiedField 레코드만 추출한 뒤에, 이를 자바 stream 에서 groupingBy 를 활용해 Map<Integer, List<ModifiedField>> 자료구조로 변환한다. 그리고 History 객체 별로 순회하면서 일치하는 Id 를 키로 갖는 List<ModifiedField> 객체를 내부 속성으로 추가한다. 이렇게 조회 로직을 구성할 경우 총 쿼리문 실행 횟수는 1+1번으로 데이터베이스 연결 횟수가 훨씬 적다.
테스트 방법 정리하기
이번 프로젝트를 진행하기 앞서, 단위 테스트와 통합 테스트를 어떻게 진행할지에 대해 많은 생각을 했다. 이전에 백엔드 클래스에서 프로덕트 코드를 작성하면서 동시에 테스트 코드를 작성하는 개발 주기를 가져갔는데, 테스트 코드에서 훨씬 많은 시간을 쏟으면서 오히려 프로덕트 코드의 설계에 신경을 못쓰는 경우가 생겼기 때문이다.
특히 데이터베이스 연결 외에는 별다른 로직이 없는 데이터 계층 (리포지토리 계층) 의 경우, CRUD 와 같은 간단한 로직의 경우 데이터베이스 의존성을 목이나 스텁으로 테스트 대역을 만들고 나면 데이터 계층만의 내부 로직이 거의 없으므로, 테스트를 진행하는 의미가 많이 없어진다고 느꼈다. 그래서 이런 경우에는 테스트를 하지 않아도 괜찮을지, 아니면 그래도 테스트를 진행해야할지 궁금했고 아래의 문서를 보게되었다.
Should I bother unit testing my repository layer
Just putting this one out for debate really. I get unit testing. Sometimes feels time consuming but I'm all for the benefits. I've an application set up that contains a repository layer and a ser...
stackoverflow.com
위 문서에서는, 데이터 계층에 대해 통합 테스트가 존재한다면 해당 계층이 테스트 커버리지에 포함이 되므로, 데이터 계층이 간단한 로직으로만 구성되어 있다면 단위 테스트를 하지 않아도 괜찮다고 말한다. 나도 이 부분에 대해 공감했기 때문에, 이번 프로젝트에서는 데이터 계층에 대한 별다른 단위 테스트 없이 진행하며, 아래와 같이 정리해보게 되었다.
[단위 테스트]
- 컨트롤러 계층 : View 로직 테스트 (@WebMvcTest + MockMvc)
- 서비스 계층 : Business 로직 테스트 (@Mock + BDDMockito)
[통합 테스트]
- 컨트롤러 + 서비스 + 리포지토리 + 데이터베이스 (RestAssured)
- 서비스 + 리포지토리 + 데이터베이스 (@JdbcTest)
- 리포지토리 + 데이터베이스 (@JdbcTest)
위와 같이 테스트를 진행할 계획을 갖고, 구현과 같은 개발 주기에 테스트를 일부 진행할 수 있었다.
다음 포스트에서는 프로젝트에서 어떤 점이 아쉬웠고, 어떻게 개선해야할지에 대해 회고를 작성하고자 한다.
'TIL' 카테고리의 다른 글
| 2022 코드스쿼드 마스터즈 코스 회고 (11) | 2022.06.19 |
|---|---|
| To-do 리스트 프로젝트 회고 - (1) 시작 (2) | 2022.04.16 |


댓글